Data Minimization in ML: Clean Room Basics [Part 3]
Overview
Data minimization is minimizing the amount and sensitivity of data is collected and processed for a given purpose. This is a broad topic with lots of sub-problems, but it is particularly interesting and pertinent when models are trained on user data.
In this series of articles, we will set up a framework for how to approach data minimization specifically in the context of training ML models. We will break this problem into well-defined sub-problems and explore solutions for each one. In this article, we explore the basics of clean rooms, specifically in the context of training. The code corresponding to this article can be found at the JustGarble repo.
Training in untrusted environments
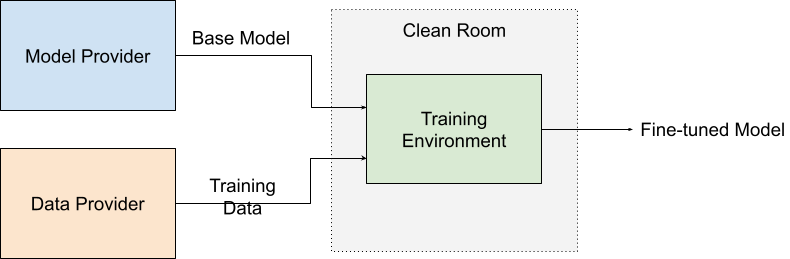
Let’s start by defining the setting. There are two entities here, the model provider and the data provider.
- The model provider provides a base model and is interested in getting a fine-tuned model. Both the base and fine-tuned models are proprietary and the model provider does not wish to share them with anyone.
- The data provider contains some sensitive data needed to fine-tuned model. The data provider does not want to provide raw access to this data to anyone.
Here is a vaguely real world example of this scenario. Let’s say that the model provider is an enterprise who wants to produce a CNN that will detect instances of lung cancer by looking at x-ray images of lungs. They already have a decent model, but it does not work well in a particular setting - say a certain population group or a particular x-ray technology. So, they are looking to engage with a hospital chain to fine-tune their model on images from this setting and hence make it more accurate. The hospital chain is okay with the training outcome, but they cannot legally share individual x-ray images of patients, and the enterprise does not want to share their base model either. So, they need to find a way to do the fine-tuning without either party revealing the information they intend to keep secret.
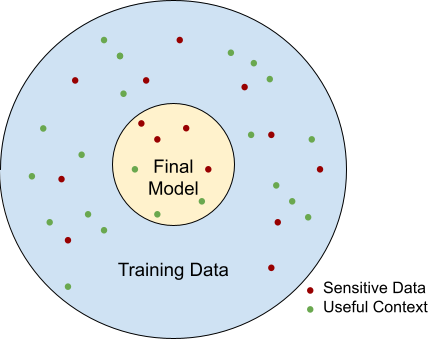
Note that some amount of information will be leaked in the final model itself. Going back to the picture in the first article, this is the information in the inner circle. What we are trying to protect is the information in the outer circle, that does not end up in the final model, and hence does not have to be revealed if the training happens in a secure environment.
Cleanrooms
A clean room, or more specifically a data clean room, refers to a kind of technology where some kind of processing can happen on sensitive data and only the intended outputs can be learnt by the parties, and no information is leaked outside of that. The concept of data clean rooms has been largely coopted by the adtech industry, but the basic principles are more general than adtech.
Conceptually, this is similar to the idea of a trusted third party (TTP), a foundational idea in the world two-party computation, as we will see in a moment. Let us say that two mutually distrusting parties want to compute something together. Here the idea is to imagine a trusted party to whom the two parties send their inputs. This party does the computation and returns back the appropriate outputs to both the parties. No other information is shared. Of course, this can extend beyond two-parties, but we will stick to the two party setting in this article.
In our setting around ML training, the data provider would send their data to the TTP, and the model provider would send the base model. The TTP would perform the fine-tuning operation and return the resulting model to the model provider. The model provider learns nothing about the training data, and the data provider does not learn anything about the output model.
Two-party computation
Secure two-party computation (and more generally secure multi-party computation) is a well understood area in Cryptography. The basic idea here is to emulate a trusted third party using various cryptographic tools. There is a lot of nuance in the definitions, around what kind of computation is allowed, how much should the parties be trusted, etc. We will not get into these details in this article. Two-party computation solutions can be built from a lot of cryptographic primitives. We will stick to one specific family of techniques, called Garbled Circuits, because of their generic nature and efficiency.
Garbled Circuits
Garbled Circuits are a fascinating idea first described by Yao in 1986. Since then, there has been a lot of interest in the area, around improving efficiency and adapting them to stronger adversary classes. There are many great sources for learning about them, including this one by Vitalik Buterin. We will be using the flavor of garbled circuits from one of my old papers, BKR13. These are particularly efficient, and can be extended easily.
The code in the JustGarble repo provides a basic implementation of this system in Golang.
What’s Next
In this article, we described the concept of clean rooms as applied to training models, and showed how the cryptographic technique of two-party computation is a natural fit with them. We introduced the concept of Garbled Circuits as a way of realizing two-party computation. In the following article, we will how to build a basic ML training solution on top of a Garbled Circuit setup.