Data Minimization in ML: Rethinking Anonymization and De-Identification [Part 2]
Overview
Data minimization is minimizing the amount and sensitivity of data is collected and processed for a given purpose. This is a broad topic with lots of sub-problems, but it is particularly interesting and pertinent when models are trained on user data.
In this series of articles, we will set up a framework for how to approach data minimization specifically in the context of training new ML models. We will break this problem into well-defined sub-problems and explore solutions for each one. In this article, we are going to dive deeper into anonymization.
A note about terminology: anonymization is a loaded word and has a precise definition when used in the context of regulatory frameworks like GDPR. Here, we are using the term a bit more loosely, to mean removing sensitive information in a broad sense. We could have picked a different term, such as de-identification or PII removal, but they have specific meanings as well, and are a lot weaker than what we are trying to accomplish.
Basics
The goal of anonymization is to remove all sensitive information from the training data. If we remove sensitive information right at the source, it has no way of making it into the final model, which is a great situation for privacy. The challenge is in being able to do this effectively, and without affecting the quality of the contextual information too much.
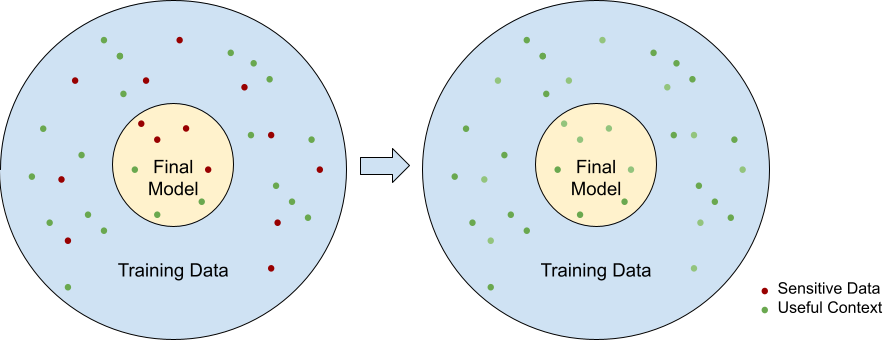
Current Approaches
Current approaches to anonymization are simplistic. They rely on pattern matching and regular expressions to identify and redact PII in the text. Slightly more sophisticated tools use techniques like Named Entity Recognition to go beyond pattern identification. However, this falls short too, as they are not effective at detecting all occurrences of the entities, especially when abbreviations and alternate names are used. Moreover, they can end up damaging a lot of useful contextual information in this process.
What’s missing?
Context: The current approaches are falling short because they have no semantic understanding of the text. There are two levels to this. The first is building a semantic model of the text, including the various objects mentioned in the text and their relationships. The second level is being able to understand how sensitive each of these objects are as well as how much useful context they provide.
Best Effort: The current approach involves making a pass over the text and returning a new blob of text as the output. There is no concept of reporting how well the anonymization process worked, or even whether it was a success or failure.
Configurability: The right level of anonymization depends on the context of the application. However, the current approaches do not provide any levers to configure how much anonymization is needed for a particular use case.
Deep Context Anonymization
The above realizations lead us to a new approach to anonymization: deep context anonymization. Here the goal is to build a semantic understanding of the text. With this and a rich model of the world we can approach anonymization from a completely different perspective, by asking: how would a reasonable huaman rewrite this text to make it anonymous? This is of course an open-ended subjective question with no definitive answer. But this also gives us flexibility in terms of how much anonymization we need, and how sensitive we are to loss of contextual information.
Leveraging LLMs
LLMs are a natural fit for deep context anonymization. They are good at understanding natural language and can be instructed to modify the text in the desired manner. However, using a zero-shot approach with a generic model is not likely to yield the best results. We need to experiment with different models, fine-tune them if needed, and try different multi-shot approaches.
The Testbed
If we want to try out and compare different models and operating conditions, we need a way to compare them objectively. That’s where the testbed project comes in. The repo contains the details of how this works, but at a basic level, the idea is to create synthetic stories of people involving specific sensitive and contextual properties. We can then test how well a given approach is, at removing sensitive information without affecting contextual information.
Current Status
From experiments with the testbed, we can get surprisingly good deep context anonymization solutions by leveraging LLMs like GPT-4 and Mistral in a few shot approach, and by breaking the task into multiple steps involving generating structured properties and reasonging about their likelihood of containing sensitive information. These techniques lead to significantly better results than the ones mentioned in the Current Approaches section. The next step is to build fine-tuned models specifically for the purpose of anonymization.