Data Minimization and Model Training: The Basics [Part 1]
Overview
Data minimization is minimizing the amount and sensitivity of data is collected and processed for a given purpose. This is a broad topic with lots of sub-problems, but it is particularly interesting and pertinent when models are trained on user data.
In this series of articles, we will set up a framework for how to approach data minimization specifically in the context of training ML models. We will break this problem into well-defined sub-problems and explore solutions for each one.
Training models on user data
Building models on user data is a common scenario in a variety of contexts such as personalization, advertising, communication assistance, etc. It is also fraught with dangers, both for the customer, in terms of privacy risks, loss of sensitive information, etc., and for the enterprise that is building the model, due to security and regulatory reasons. We can visualize this better with a simple albeit simplistic mental model - let us say that the user data in question has two kinds of features.
- Sensitive information that is not needed for the purpose of the application, but is harmful if it makes its way into the model or otherwise gets leaked to attackers.
- Contextual information that is actually relevant for the purpose of the application.
To make this more concrete, let us say we are building a shopping assistant app that learns about the user’s preferences from their social media posts. For this application, understanding the socio-economic situation of the user is helpful. To that end, let us say that the following sentence is part of the training data:
I drove my Ferrari from my house in Beverly Hills to my office in Santa Monica.
On the one hand, this sentence provides a lot of information about the socio-economic status of the user. But on the other hand, this information is so specific that it can be used to effectively dox the person, or at least get quite close. We want to find ways to extract the useful context in a piece of information without bringing in the overly-specific details that do not add any useful context anyway. For instance, a sentence like the one below will give us more or less the same level of contextual information, but without revealing sensitive information about the user.
I drove expensive luxury car from my house in an upscale coastal neighborhood to my office located closeby.
Stepping back, the fundamental question we are interested in solving is: “How can we build models from user data that are rich in contextual information but have minimal amounts of sensitive data?”
From the framing of this question, it should be clear that we are looking at a harm reduction approach here. We accept that models built on user data will have some amount of sensitive information in them. But we can drive this down to a meaningful extent.
Training and Inference
If we think about this question carefully, we can see that there are two aspects to it, centered around what happens at training time, and what happens at inference time.
At training time, we should be worried about how much sensitive information is in the training data. This information is available to the training environment (which might be untrusted or semi-trusted), and might be available to attackers who compromise the training infrastructure.
Post training, we should be worried about how much sensitive information has made it into the final model, and is hence available to malicious users and other types of attackers who do not have access to the training data, but do have access to the final model.
The following picture helps visualize the two issues.
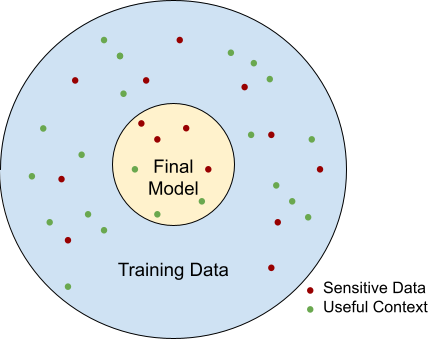
Solutions
In the rest of the articles in this series, we are going to look at two broad classes of solutions: anonymization and clean rooms.
Anonymization involves processing the training data so that the sensitive information is removed. There is some prior work around this, but as we explore further, we will find that the existing approaches are too basic, and that there is value in exploring deep context anonymization, by which we mean getting rid of sensitive information while keeping an eye on the loss of useful context. In the picture above, the purpose of anonymization is reducing the number of red dots before starting the training process. Note: Anonymization is a loaded word and has a precise definition when used in the context of regulatory frameworks like GDPR. Here, we are using the term a bit more loosely, to mean removing sensitive information in a broad sense.
Clean rooms are applicable in the setting where the training environment is untrusted/semi-trusted. This is relevant if the data involved is particularly sensitive, such as medical data, and when the entity that wants to build and use the model is different from the entity that provides the data. The data provider does not want to share their data in its entirety, but they are okay with some context seeping into the model. In other words, they are okay with sharing the inner circle in the diagram above but not the outer circle. Clean rooms are a well-studied context as well, but when we tailor the setting to model training, we find that we can build solutions that are more efficient and simpler.