Demystifying AI Governance: Chokepoints [Part 2]
Overview
AI governance involves providing guardrails for safely using AI systems. This can seem like an obtuse topic, but once we start approaching it systematically, we find that it breaks into concrete subproblems. A lot of these map to well-understood problems in cybersecurity, with a few twists here and there; the rest are novel, but can be framed as clear requirements.
The first article in this series covered the basics, breaking down AI governance into a set of specific problems. This article dives deeper into building a solution framework.
The Setting
Before diving into the solution, let’s describe the setting. Because we want a comprehensive AI governance solution that covers all use cases, we should keep the setting as generic as possible. We are looking at an enterprise setting, with a production infrastructure (prod), consisting of services running on a cloud platform, and a corporate infrastructure (corp), consisting of employee devices (laptops, phones, etc.).
-
AI System: This is our abstraction for covering all shapes of AI related systems, including internal models and external, vendor-provided models. These systems will interact with corp and prod services across the infrastructure.
-
Calling Service: This is the service interacting with the AI system. It makes requests to the AI system and gets back responses, i.e., the AI system is a remote service from the perspective of the calling service. These interactions could be part of the training phase, inference phase, or some other operational activity. This service might be running in production, or on an employee laptop. It could even be a chatbot-type application running in the browser. This abstraction extends to all these settings.

Chokepoints
The first article introduced the paradigm of visibility and control, i.e., all the component problems that fall within AI governance essentially involve gaining visibility or control over some aspect of an AI system - this could be the model itself, training data, inference inputs and outputs, identity and permissions of the caller, etc.
A natural mechanism for achieving this type of visibility and control is a chokepoint. If we can ensure that all interactions with all AI systems in an enterprise passed through a single (logical) chokepoint, that would give us a way to bootstrap various visibility and control mechanisms.
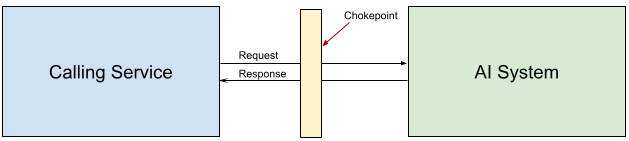
Of course, building a pervasive chokepoint that wraps all AI systems is no easy challenge. If done wrong, this could easily become a point of failure and compromise for the overall infrastructure. Our goal with AI governance is ultimately reducing AI-related risks for the business, and a badly designed chokepoint might be a net negative from this perspective.
Design Criteria
The top-level goal here is to materialize a chokepoint that is comprehensive enough to cover all the problems within AI governance, but at the same time, robust and secure enough that it does not become a point of failure or compromise. Moreover, we want to minimize the incremental cost of AI governance as much as possible and to that end reuse existing solutions wherever we can. From these top-level goals, we can frame some concrete design goals:
- The solution should work with all AI systems - either out of the box, or with minimal extra work.
- No active components in any critical path.
- No elevated access priviliges.
- The solution should seamlessly integrate with existing workflows.
The rest of this article and follow-up articles cover the design of such a system. For simplicity, the articles describe a solution specific to AWS.
Wrappers + Controller
Realizing the chokepoint in a centralized manner, say, via a Gateway, is a good thought exercise, but it does not work in practice - such a gateway would be a single point of failure and compromise. An alternative to this is to imagine such a gateaway, but have it run along with the calling service, as a wrapper or a sidecar. In other words, every call to an AI system should be wrapped by a layer of logic that essentially does the same checks the gateway would have done. But now, this logic lives alongside the caller, instead of an external location. The simplest version of such a wrapper would be a library - for instance a Python library vended via pip. Developers can then add this a dependency in their service.
The wrapper code is in the wrapper directory in the repo. We will explore this in more detail in the coming articles.
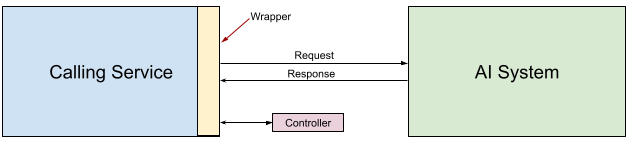
These wrappers cannot function in isolation. They need to be hydrated with relevant configs and metadata, and they need a sink where they can send data and telemetry. Both these functions are performed by a centralized entity, the controller. In the simplest case, this controller can be a passive component, such as an S3 bucket. The wrappers pick up the configs they need from this bucket, and write back audit logs and event information to the same bucket. Controllers can get more complicated than this, and we will explore them in a later article, but for now, a simple S3 bucket will be sufficient for our purposes.
This simple pip-vended Python library and a S3 bucket might not seem like much, but it in the next article we show that it gives us a lot of the visibility and control we need.
Recap and Next Steps
We started with the idea that AI government boils down to visibility and control, and then argued that a well-designed pervasive chokepoint is a great way to get visibility and control over a set of systems, such as all the AI systems in an enterprise. We then sketched how such a chokepoint can be implemented as a wrapper/controller design, and realized by simple components, such as a simple Python library acting as the wrapper and an S3 bucket acting as the controller.
In the next article, we show how this simple Python library + S3 bucket based implementation can solve a bunch of AI governance features. Following that, we show auth and access control can be used to ensure that this wrapper/controller chokepoint is pervasive.