Demystifying AI Governance: The Basics [Part 1]
Overview
AI governance involves providing guardrails for safely using AI systems. This can seem like an obtuse topic, but once we start approaching it systematically, we find that it breaks into concrete subproblems. A lot of these map to well-understood problems in cybersecurity, with a few twists here and there; the rest are novel, but can be framed as clear requirements.
This article, the first in a series on demystifying AI governance, gives a high-level overview of the area. Our eventual goal is to build a simple but extensible AI governance platform. The code is available here, and we’ll keep referencing specific parts of it as we go.
Life of a Model
The best place to start towards demystifying AI Governance is understanding how AI models are used in enterprises. Models can be built from scratch (e.g. simple neural nets), or pre-trained with some later fine-tuning (e.g. ResNet family). They can be on-prem (e.g. HuggingFace models) or hosted at a vendor (e.g. GPTs). They can be used to power customer-facing features and/or internal tools. Here are some of the stages within a model’s lifecycle in an enterprise.
Model Introduction: A model starts becoming a concern when it is being used as part of some functionality, especially if it involves sensitive customer/user/employee data. All models have associated risks - security, privacy, ethics, etc., but some models are safer than others, especially in certain situations.
Training: The data used to train models can lead to restrictions on how the model is used. For instance, applications built on models trained on raw user data must include mechanisms to respect data subject rights, such as the right to be forgotten.
Inference: Models can represent an alternate plane of access to the data they were trained on. For instance, a model trained on internal documents and made available to all employees invalidates whatever access control policies were applied on the docs. Model outputs can contain abusive, inaccurate, or inappropriate information, and usually need to be filtered.
Continued Operation: Models can start showing degraded performance over time, a phenomenon known as model drift. This can affect the safety properties of the models.
Vendor-hosted models: With vendor-hosted models, there are additional issues, as vendors are external third parties. Preventing sensitive data from reaching the vendor via model inputs at training/inference time is important. Preventing abusive prompts is also important and usually stipulated as a contractual requirement by the vendor.
Breaking into subproblems
We can breakdown AI governance into sub-problems by analyzing the security issues in each of the stages in the model lifecycle sketched above.
A common joke in cybersecurity is that every problem can be framed as either monitoring or controlling access to something. Monitoring/ visibility type solutions are usually easy to implement but cannot prevent bad outcomes. Nevertheless, they might be sufficient in some cases. Control solutions have to be more robust, and are hence more expensive to build. AI governance is no different in this regard.
The following picture takes the problems sketched in the previous section and frames them as problems around visibility/control.
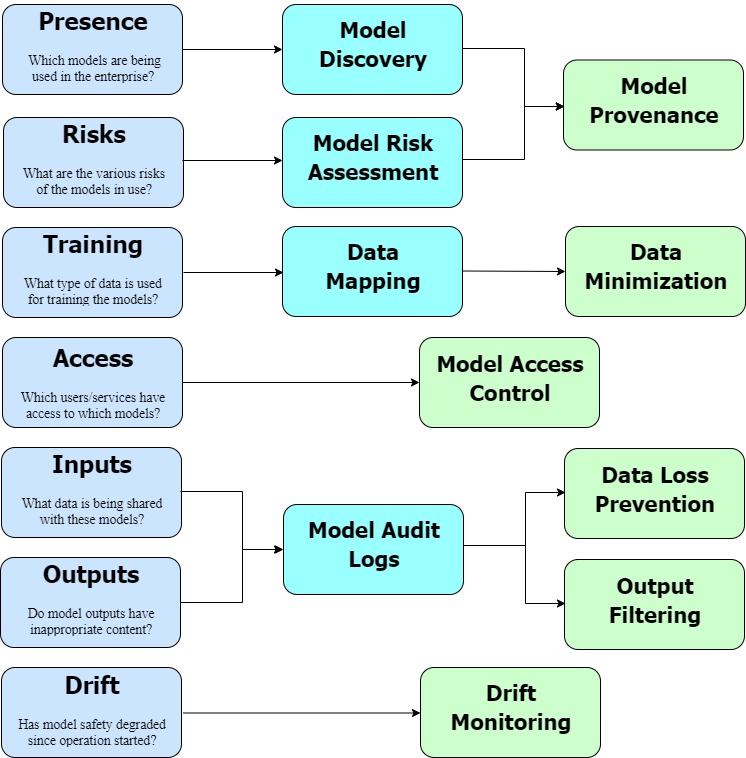
Let us look at these problems in more detail.
Model Discovery is about finding the models that are in use within the enterprise. It parallels familiar problems such as Data Mapping and Vendor Discovery. Solutions include manual information gathering from engineering teams or automated methods like Code Scanning.
Model Provenance refers to standardizing the ways in which models can be procured (both on-prem and vendor-provided models). This is a subcategory of supply chain security and solutions follow a similar template - have a centralized repository of approved components (in this case models) and control how components are added/updated within this repository.
Model Risk Assessment ensures that model risks remain within acceptable bounds. This is one of the more unique subproblems within AI governance, although it bears some similarities to black box testing, pen testing, and other offensive security techniques.
Data Mapping entails creating a map of sensitive data locations within the infrastructure. It is a foundational challenge in privacy and a prerequisite for addressing other issues. In the context of AI governance, the additional complexity lies in tracking which data sources are utilized to train specific models.
Data Minimization covers a broad family of techniques including pseudonymization, anonymization and synthetic data generation. In this context, data minimization serves a specific purpose, to unlink the training data from the underlying users and hence reduce restrictions on the resultant models.
Model Access Control involves controlling which principals (users, services, etc.) get access to which models. This maps to internal or third-party access control, depending on whether the model in question is on-prem or vendor-hosted. The challenge is in avoiding creating shadow access planes, and instead capture these rules in the existing IAM graph(s) in the org.
Model Audit Logs capture the details of the training and inference operations with the models. These logs are invaluable for meeting regulatory requirements and for incident forensics. Audit Logs in general are a fairly well understood problem. The challenge is around leveraging these existing tools for AI models instead of creating new, incongruent tooling.
Data Loss Prevention is about ensuring that sensitive data belonging to the enterprise does not get inadvertently shared with AI vendors, or otherwise becomes part of the training corpora of internal models. This is also a well understood problem in general, with extensive solutions. The challenge is in adapting these existing tools to AI-specific use cases such as training and inference, and ensuring consistent usage across the organization.
Abusive Prompt Filtering is a novel problem with AI systems, especially LLMs. It involves detecting and preventing abusive/inappropriate prompts reaching the model.
Output Filtering, i.e., ensuring that model outputs adhere to the policies of the organization and larger regulations, is a new problem with AI applications. Our understanding of this problem as well as the solution landscape are both evolving. The best approach here is adopting a viable solution among the available options and watching the landscape for advancements.
Drift Monitoring is another novel AI problem and involves continuously monitoring model safety performance metrics and acting when these metrics drop below acceptable thresholds.
What Next
The tldr; of this post is that AI Governance can be broken into sub-problems which map to well-understood problems in cybersecurity. In the next post, we’ll take this one level further and explore how we can extend existing solutions for these sub-problems to the AI governance use-cases.